
Wstęp
Hurtownie danych to systemy, które, w dużym uproszczeniu, pobierają dane z wielu systemów źródłowych, a następnie przy pomocy różnych transformacji konsolidują je do jednej bazy danych zwanej właśnie hurtownią danych. Na podstawie tak zgromadzonych informacji biznes otrzymuje pełny zestaw danych o całej organizacji zwaną jedną wspólną wersją prawdy. Dane zgromadzone w ten sposób dają możliwość przygotowywania analiz i raportów oraz pozwalają podejmować na ich podstawie trafne decyzje. W rzeczywistym wdrożeniu hurtownia danych (w przypadku wykorzystania narzędzi firmy Microsoft) to zestaw składający się z ogromnej ilości danych, przepływów i transformacji danych przygotowanych w SQL Server Integration Services. Zestaw ten możemy rozszerzyć o równie dużą ilość transformacji i przepływów stworzonych przy pomocy procedur składowanych w SQL Server. Całość danych będzie się przemieszczała z wykorzystaniem dziesiątek lub setek różnych tabel pośrednich zanim trafią do właściwej hurtowni danych.
Jaki jest z tego wniosek? A no taki, że na sukces hurtowni danych wpływ ma ogromna ilość elementów, w których odzwierciedlona jest logika biznesowa przez co nawet niewielka zmiana powinna być rzetelnie przetestowana oraz zweryfikowana zanim zostanie opublikowana w środowisku produkcyjnym. Bardzo niewiele projektów posiada testy automatyczne czy też działy QA, które będą potrafią właściwie sprawdzić wprowadzane zmiany. Mały odsetek tego typu projektów jest również prawidłowo prowadzonych pod względem zarządzania kodem oraz procesu publikowania zmian, a tematy takie jak DevOps, Continous Integration czy Continuous development w kontekście rozwiązań klasy Business Inteligence zaczęły być szerzej poruszane na przestrzeni zaledwie ostatnich miesięcy. Co prawda tematy te są bardzo obszerne i zapewne zostaną jeszcze tutaj opisane, natomiast warto w tym miejscu zwrócić uwagę, że hurtownia danych, a szczególnie duże projekty, składają się z wielu drobnych elementów gdzie każdy z nich oddziałuje na inny i ryzyko ewentualnych błędów oraz problemów jest naprawdę duże.
Problem polega na tym, że w przypadku ewentualnego błędu lub opublikowania nieprawidłowej zmiany możemy otrzymać błędne wyniki na raportach i analizach, a z racji wielu różnych tabel, obszarów, raportów i analiz wychwycenie ewentualnych błędów może nie być zadaniem trywialnym. Niniejszy artykuł będzie skupiał się na omówieniu ewentualnych konsekwencji, które mogą wynikać z opublikowania do rozwiązania niepoprawnej zmiany lub ewentualnych błędów regresji. Omówiony zostanie również pomysł i jego wstępna realizacja w formie Proof of Concept (POC), która powinna pomóc, o ile nie wyeliminować takie błędy lub przynajmniej szybko je odkryć co umożliwi szybsze działanie. Wartością dodaną będzie również możliwość śledzenia zmian w danych.
Problem i konsekwencje
Nawet drobna zmiana w procesie ETL w przypadku niepowodzenia może spowodować bardzo poważne konsekwencje. W przypadku zmiany procedury dane mogą być ładowane błędnie i mogą sprawić, że raporty staną się bezużyteczne. Specyfika powstawania tych błędów jest taka, że niestety nie zawsze będzie można je wychwycić na pierwszy rzut oka. Innym problemem, który możemy spotkać to błąd stojący po stronie źródła danych. Odczytując dane bezpośrednio z tabeli w systemach źródłowym nie możemy być w stu procentach przekonani co do ich jakości. Zdarza się również, że bardzo często korzystamy z widoków dostarczanych przez inny dział/zespół/dostawcę, z różnego rodzaju serwisów pośredniczących czy plików płaskich generowanych automatycznie lub półautomatycznie. Ponownie jak wyżej, również w przypadku błędu po stronie źródła, proces ETL może mimo wszystko załadować dane do hurtowni danych mimo, że są one nieprawidłowe. Niektóre błędy będą łatwe do wychwycenia i widoczne w logach ETL czy po prostu na raportach. Część z nich jednakże może być na tyle mała, że nie będzie widoczna na raporcie – ale w ostatecznym rozrachunku może powodować narastające różnice i przekazanie błędnych informacji.
Kiedy już uda się zidentyfikować problem należy go rozwiązać. Pierwszym krokiem będzie oczywiście przygotowanie odpowiedniej poprawki do procesu ETL. Drugim natomiast, będzie zapewne poprawienie błędnie załadowanych danych, czyli przeładowanie danych w hurtowni. W przypadku, gdy proces ETL przewiduje aktualizacje wierszy będzie to oczywiście jak najbardziej możliwe. Problem pojawia się jednak w przypadku dużych i skomplikowanych hurtowni danych, gdzie przeładowanie danych z ostatnich tygodni dla jednej tabeli może wymagać wielu godzin oraz wpłynąć na wyniki innych tabel, które następnie również trzeba będzie “przeładować”. Odświeżeniu mogą również podlegać systemy raportowe czy na przykład kostki analityczne. Jeszcze większy problem może pojawić się wówczas, gdy w chwili pojawienia się problemu na podstawie danych z hurtowni zostaną przygotowane raporty finansowe oraz zostanie “zamknięty miesiąc”… Jak widać czas uchwycenia ewentualnego problemu jest krytyczny.
Idea
Data Verification Framework (DVF) to pomysł na narzędzie, które powinno pomóc wychwycić ewentualne błędy lub duże zmiany w danych w bardzo krótkim czasie. Powinno ono pozwalać na obserwację oraz analizę zmiany w danych w poszczególnych tabelach i w przypadku wykrycia niepokojących zmian oraz odstępstw na wysłanie odpowiednich komunikatów. Cała idea polega na wykorzystaniu komponentu Data Profiling Task, który jest dostępny w SQL Server Integration Services. Podobnie jak zostało to pokazane w jednym z wcześniejszych postów (zobacz: https://pl.seequality.net/biml-i-data-profiling-task-automatyczne-profilowanie-wszystkich-tabel-w-bazie-danych-nieskonczone/), aby zautomatyzować pracę tego narzędzia oraz zapewnić dużą uniwersalność zostanie wykorzystany język BIML do automatycznego generowania pakietu, który będzie profilował tabele. Po uruchomieniu pakietu dane wynikowe z Data Profiling Task zostaną zapisane do bazy danych w sposób taki, aby możliwa była ich analiza. Szczegółowy opis Data Profiling Task oraz BIML znajduje się we wcześniej wspomnianym poście, natomiast poniżej znajduje się schemat rozwiązania oraz więcej szczegółów na temat jego działania.
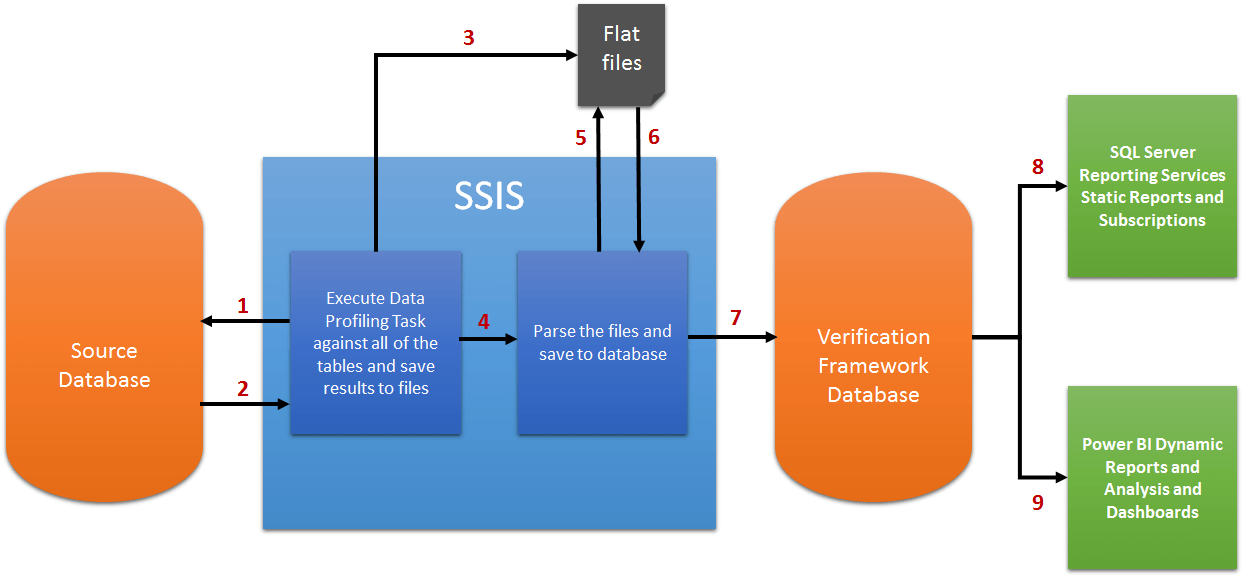
- Source Database – źródłowa baza danych dla której uruchomiony będzie DVF. Docelowo będzie to dowolna baza danych w dowolnym środowisku.
- Execute Data Profiling Task against all of the tables and save the results to files – wygenerowany przez BIML pakiet, który dla każdej tabeli w bazie danych (lub zgodnie z konfiguracją) uruchomi Data Profiling Task (1), pobierze dane (2) oraz oraz zapisze rezultaty do plików wynikowych (3).
- Parse the files and save to database – kolejny pakiet SSIS (4), który pobierze wcześniej wygenerowane pliki (5), odczyta (6) oraz “sparsuje” do postaci takiej, która umożliwi ich zapisanie w bazie danych (7).
- Verification Framework Database – baza danych VFD, która będzie zawierała dane pochodzące z plików Data Profiling Task. Zostaną tam zgromadzone wszystkie dane z plików metodą przyrostową, która umożliwi później na analizę zmian w czasie oraz wykrywanie ewentualnych błędów.
- SQL Server Reporting Services Reports and Subscriptions – raporty przygotowane w SSRS, które pozwolą na szybkie sprawdzenie statystyk oraz kontrolę danych w bazie. W przypadku wykrycia niebezpiecznych odstępstw subskrypcje będą w stanie wysłać odpowiednie komunikaty do odpowiednich osób
- Power BI Dynamic Reports and Analysis and Dashboards – bardziej zaawansowane raporty oraz analizy przygotowane z wykorzystaniem Power BI.
W przypadku jakichkolwiek zmian w źródłowej bazie danych uruchomienie skryptu BIML samoistnie wygeneruje pakiet, który te zmiany uwzględni. Framework nie powinien zatem powodować większego obciążenia dla programistów. Dodatkowo użycie języka R w Reporting Services oraz Power BI powinno pozwolić na wykorzystanie algorytmów odkrywania wiedzy czy też analizę szeregów czasowych, dzięki czemu ewentualne wykrywanie błędów powinno być stosunkowo szybkie oraz wiarygodne. Zgromadzone informacje powinny pozwoli na analizę:
- ilość oraz procentu wartości NULL w kolumnach
- podstawowych statystyk atrybutów (minimum, maksimum, średnia, odchylenie standardowe) dla każdej kolumny liczbowej oraz atrybutu typu data
- podstawowych statystyk o długości pól tekstowych (minimum, maksimum) oraz procentowym podziale długości każdej kolumny tekstowej
- analizę wartości kolumn tekstowych oraz BIT
- wartości pojawiających się najczęściej z uwzględnieniem ich udziału procentowego w atrybucie
- potencjalnych wzorców w danych tekstowych. Wynikami będą konkretne wartości lub wyrażenia regularne oraz ich procentowy udział względem wszystkich wartości w kolumnie
- zależności pomiędzy atrybutami – na przykład nazwa państwa i kod ISO państwa zostanie zwrócona jako para, która jest zależna i powinna być zgodna w stu procentach.
Takie informacje powinny umożliwić faktyczne śledzenie zmian w danych oraz szybkie wychwytywanie ewentualnych błędów.
Przechowywanie danych (baza danych)
Struktura bazy danych, która została przygotowana do przechowywania danych dla DVF wynika wprost z budowy plików wynikowych. Dla każdego trybu działania (zadania) Data Profiling Task dedykowane są dwie tabele, czyli “*Request” oraz “*Output” – kolejno dla żądania wykonania danego zadania oraz dla wyników jego działania. Dla kontroli działania dodane zostały tabele “ExecutionLog”, która przechowuje informacje o historii wykonywania DVF oraz “FileLog”, która przechowuje informacje o powodzeniu/niepowodzeniu odczytu plików wynikowych. Wszystkie obiekty zgrupowane zostały w dwóch schematach “internal”, który zawiera obiekty konieczne dla działania narzędzia oraz “Reporting”, który służy jako warstwa dostępowa dla użytkowników – domyślnie wszystkie obiekty powinny zostać wyeksponowane dla użytkowników za pomocą tego schematu. Dodatkowo do schematu “Reporting” mogą zostać dodawane dodatkowe zapytania dla raportów.

Schemat bazy danych został umieszczony w solucji całego rozwiązania jako “Database Project” co powinno zapewnić prostą publikację oraz względnie prostą aktualizację w przypadku zmian w kolejnych wersjach frameworka.
Gromadzenie statystyk (BIML)
Sam skrypt do generowania takiego pakietu został opisany we wspomnianym wcześniej poście, natomiast uległ on drobnej modyfikacji. Jest to stosunkowy prosty skrypt, który pobiera listę tabel ze wskazanej bazy danych oraz generuje zadania typu Data Profiling Task dla każdej z nich.
<Biml
xmlns="http://schemas.varigence.com/biml.xsd">
<#
string ConnectionString =@"Data Source=localhost\sql2016;Initial Catalog=AdventureworksDW2016CTP3;Integrated Security=True;";
List<String>
tables = new List<String>
();
using(SqlConnection connection = new SqlConnection(ConnectionString))
{
string query = @"
SELECT QUOTENAME(SCHEMA_NAME(sOBJ.schema_id)) AS SchemaName,
sOBJ.name AS [TableName],
SUM(sPTN.rows) AS [RowCount]
FROM sys.objects AS sOBJ
INNER JOIN sys.partitions AS sPTN
ON sOBJ.object_id = sPTN.object_id
WHERE sOBJ.type = 'U'
AND sOBJ.is_ms_shipped = 0x0
AND index_id < 2 -- 0:Heap, 1:Clustered
GROUP BY sOBJ.schema_id,
sOBJ.name
ORDER BY 3 DESC;
";
using(SqlCommand command = new SqlCommand(query, connection))
{
connection.Open();
using (SqlDataReader reader = command.ExecuteReader())
{
while (reader.Read())
{
tables.Add(reader.GetString(1));
}
}
}
}
#>
<Connections>
<AdoNetConnection Name="SOURCE_DATABASE" Provider="System.Data.SqlClient.SqlConnection, System.Data, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" ConnectionString="Data Source=localhost\sql2016;Initial Catalog=AdventureworksDW2016CTP3;Integrated Security=True;" />
<# foreach (string table in tables) { #>
<FileConnection Name="OutputFile<#=table#>" FileUsageType="CreateFile" FilePath="C:\test\ProfilerResults\<#=table#>.xml" />
<# } #>
</Connections>
<Packages>
<Package Name="CheckDataTypes" ConstraintMode="Linear" ProtectionLevel="EncryptSensitiveWithUserKey">
<Tasks>
<Container Name="DIMS">
<Tasks>
<# foreach (string table in tables) { #>
<DataProfiling Name="<#=table#>" OverwriteDestination="true">
<FileOutput ConnectionName="OutputFile<#=table#>" />
<ProfileRequests>
<ColumnNullRatioProfileRequest Name="NullRatioReq" ConnectionName="SOURCE_DATABASE" SchemaId="dbo" TableId="<#=table#>" />
<ColumnStatisticsProfileRequest Name="StatisticsReq" ConnectionName="SOURCE_DATABASE" SchemaId="dbo" TableId="<#=table#>" />
<ColumnLengthDistributionProfileRequest Name="LengthDistReq" ConnectionName="SOURCE_DATABASE" SchemaId="dbo" TableId="<#=table#>" />
<ColumnValueDistributionProfileRequest Name="ValueDistReq" ConnectionName="SOURCE_DATABASE" SchemaId="dbo" TableId="<#=table#>" />
<ColumnPatternProfileRequest Name="PatternReq" ConnectionName="SOURCE_DATABASE" SchemaId="dbo" TableId="<#=table#>" />
</ProfileRequests>
</DataProfiling>
<# } #>
</Tasks>
</Container>
</Tasks>
</Package>
</Packages>
</Biml>
<#@ template language="C#" hostspecific="true"#>
<#@ import namespace="System.Data" #>
<#@ import namespace="System.Data.SqlClient" #>
Oczywiście w finalnej wersji skrypt zostanie rozszerzony o tabelę konfiguracyjną oraz wykorzystanie widoków.
Przetwarzanie statystyk (SSIS)
Wygenerowany za pomocą BIML pakiet SQL Server Integration Services stanie się pełnoprawnym pakietem, który będzie w stanie pobrać statystyki dla każdej tabeli.

Oprócz powyższego dodany został drugi pakiet, który odpowiedzialny jest za przeczytanie wszystkich plików, ich sparsowanie oraz zapisanie w bazie danych wraz z podstawowymi logami.

Samo parsowanie zostało obsłużone za pomocą komponentu Script Task i języka C#, a wynikiem działania skryptu są dwa przepływy z danymi dla każdego zadania/funkcji Data Profiling Task – pierwszy zbiór danych będzie zawierał informacje o żądaniu, natomiast drugi o rezultacie konkretnego zadania.

Do parsowania została wygenerowana odpowiednia klasa, a następnie plik wynikowy, który jest zwykłym plikiem XML jest odczytywany i konwertowany do tej klasy.
string currentFilePath = Variables.vCurrentFile;
string xml = File.ReadAllText(currentFilePath);
bool parseFailed = false;
DataProfile allProfilerResults = null;
try
{
allProfilerResults = xml.ParseXML<DataProfile>();
}
catch (Exception exc)
{
ComponentMetaData.FireWarning(0, "Error during reading the file source. " + currentFilePath + "Exception", exc.Message + " , Inner exception: " + exc.InnerException, "", 0);
parseFailed = true;
}
W dalszej części kodu standardowo tworzony jest przepływ danych dla każdego elementu z podstawową obsługą błędów.
try
{
ColumnLengthDistributionProfileOutputBuffer.AddRow();
ColumnLengthDistributionProfileOutputBuffer.ColumnCodePage = item.Column.CodePage;
ColumnLengthDistributionProfileOutputBuffer.ColumnIsNullable = item.Column.IsNullable;
ColumnLengthDistributionProfileOutputBuffer.ColumnLCID = item.Column.LCID;
ColumnLengthDistributionProfileOutputBuffer.ColumnMaxLength = item.Column.MaxLength;
ColumnLengthDistributionProfileOutputBuffer.ColumnName = item.Column.Name;
ColumnLengthDistributionProfileOutputBuffer.ColumnPrecision = item.Column.Precision;
ColumnLengthDistributionProfileOutputBuffer.ColumnScale = item.Column.Scale;
ColumnLengthDistributionProfileOutputBuffer.ColumnSqlDbType = item.Column.SqlDbType;
ColumnLengthDistributionProfileOutputBuffer.ColumnStringCompareOptions = item.Column.StringCompareOptions;
ColumnLengthDistributionProfileOutputBuffer.DataSourceID = item.DataSourceID;
ColumnLengthDistributionProfileOutputBuffer.IgnoreLeadingSpace = item.IgnoreLeadingSpace;
ColumnLengthDistributionProfileOutputBuffer.IgnoreTrailingSpace = item.IgnoreTrailingSpace;
ColumnLengthDistributionProfileOutputBuffer.IsExact = item.IsExact;
ColumnLengthDistributionProfileOutputBuffer.MaxLength = item.MaxLength;
ColumnLengthDistributionProfileOutputBuffer.MinLength = item.MinLength;
ColumnLengthDistributionProfileOutputBuffer.ProfileRequestID = item.ProfileRequestID;
ColumnLengthDistributionProfileOutputBuffer.TableDatabase = item.Table.Database;
ColumnLengthDistributionProfileOutputBuffer.TableDataSource = item.Table.DataSource;
ColumnLengthDistributionProfileOutputBuffer.TableRowCount = item.Table.RowCount;
ColumnLengthDistributionProfileOutputBuffer.TableSchema = item.Table.Schema;
ColumnLengthDistributionProfileOutputBuffer.TableName = item.Table.Table;
}
catch (Exception exc)
{
//throw exc;
ComponentMetaData.FireWarning(0, "Exception", exc.Message + " , Inner exception: " + exc.InnerException, "", 0);
}
Oba pakiety wywoływane są z pojedynczego pakietu rodzica.

Dzięki użyciu BIML oraz C# do generowania statystyk oraz ich parsowania i zapisywania do bazy danych wszystkie pakiety są stosunkowe mało skomplikowane oraz łatwe do zrozumienia.
Przykład raportów statycznych (SSRS)
Zgromadzone dane są zapisywane do bazy danych. Dzięki temu można wykorzystać dowolne narzędzia raportowe, aby przygotować szybki dostęp do najważniejszych informacji oraz, aby skrócić czas wyszukiwania potencjalnych błędów. Przykładem takiego raportu może być poniższy, który pozwala śledzić ilość pustych wartości w danych atrybutach.

Dzięki domyślnym parametrom użytkownik jest w stanie zobaczyć tylko i wyłącznie te atrybuty w bazie danych, których stosunek wartości pustych rzeczywiście zmieniał się w czasie. Zielony kolor informuje, że w danym okresie ilość wartości NULL zmalała, natomiast kolor czerwony informuje, że ilość takich wartości wzrosła. Dzięki temu jesteśmy w stanie szybko wychwycić te anomalie, które mogą świadczyć o błędach w źródłach danych lub wadliwej zmianie w kodzie ETL. Oczywiście liczba dostępnym raportów zostanie powiększona.
Przykład raportów dynamicznych i analizy (Power BI)
Innym przykładem raportów są raporty przygotowane w Power BI. Jako wzór jeszcze raz analiza wartości NULL w kolumnach. Na samym początku ogólny przegląd jakości danych w bazie danych oraz informacje o ilości takich wartości w tabelach.

Drugi przykład raportu dotyczy porównania długości łańcuchów w poszczególnych atrybutach. W przypadku gdy dana kolumna nie dopuszcza wartości NULL wychwycenie ewentualnych problemów może być jeszcze trudniejsze. Wykres pokazuje dla konkretnej tabeli i konkretnego atrybutu zmianę w rozkładzie długości pojedynczego atrybutu. Jak widać w ładowaniu hurtowni o ID 12 występuje anomalia. W poprzednich ładowaniach rozkład był zbliżony do rozkładu naturalnego, natomiast w przypadku ładowania o ID 12 wszystkie wiersze zostały zaktualizowane oraz ich długość wynosiła 2 co znowu może świadczyć o błędach w danych źródłowych lub błędnej zmianie w ETL.

Dzięki Power BI możliwe będzie również dodanie analizy danych sensu stricte oraz dzięki wykorzystaniu języka R i modeli predykcyjnych ewentualne wykrywanie problemów ex-ante, a nie post-factum.
Kolejny etapy i usprawnienia POC
Powyższy przykład rozwiązania to oczywiście tylko Proof Of Concept i oczywiście nie jest jeszcze gotowy do użycia. Mimo wszystko będzie ono na bieżąco, w wolnych chwilach, rozwijany i dlatego też zapraszam to śledzenia repozytorium oraz strony projektu na GitHub. Póki co zauważone zostały oraz planowane są następujące zmiany:
- dodać możliwość profilowania widoków
- dodać tabele konfiguracyjne, które pozwolą utworzyć listę tabel/widoków, które powinny zostać poddane profilowaniu, a które nie
- dodać możliwość profilowania dla zakresu danych, nie tylko dla całej tabeli – tabele faktów w hurtowni danych mogą być ogromne i profilowanie całej tabeli może być bardzo czasochłonne. Możliwość profilowania tylko zestawu danych, na przykład danych z ostatniego miesiąca, powinna znacznie skrócić czas profilowania i zapewnić taką samą porcję informacji. Dodać odpowiednią tabelę konfiguracyjną, która pozwoli wskazać, która kolumna powinna zostać użyta jako filtr dla poszczególnych tabel
- przygotować raporty statyczne dla wszystkich statystyk w SSRS
- przygotować raporty dynamiczne dla wszystkich statystyk w Power BI
- przygotować dashobardy w powerbi.com i SSRS, które umożliwią szybki podgląd błędów z wszystkich dostępnych statystyk
- dodać algorytmy odkrywania wiedzy, które pozwolą przewidzieć ewentualne niepokojące zmiany w statystykach tabel
- przygotować aplikację, która pozwoli na proste konfigurowanie oraz instalację rozwiązania
- przetestować oraz dodać wsparcie dla większej ilości edycji SQL Server
- dodać wsparcie dla innych baz danych jak np Oracle
- przygotować pakiet instalacyjny
Zmiany te, jako zadania, zostały również dodane do projektu na GitHub. W przypadku kroków milowych oraz dużej ilości kluczowych zmian powstanie nowy post z krótkim podsumowaniem oraz przypomnieniem o projekcie.
Inne narzędzia oraz metody
Według mojego stanu wiedzy na rynku ciężko spotkać produkt, który pozwalałby na taką weryfikację danych oraz śledzenie zmian w danych. Oczywiście dobrym pomysłem jest stosowanie testów oraz wykorzystywanie na przykład tSQLt w projekcie, natomiast za pomocą tSQLt nie zgromadzimy tak szerokiej informacji o danych oraz ich zmianie. Dodatkowo dane testowe nie zawsze pokrywają wszystkie przypadki biznesowe i ciężko napisać testy, które pokryją wszystkie przypadki. Należy również pamiętać, że każdy test wydłuża proces wprowadzenia zmian na produkcję, ale mimo wszystko testy powinny być pisane.
Osobiście spotkałem się z pomysłem przygotowywania dodatkowych testów, w tym przypadków po prostu zapytań, które pokrywały jeden, konkretny przypadek biznesowy. Takie testy porównywały na przykład liczbę nowych klientów, która pojawiła się na “Stage” oraz liczbę klientów w tabeli wymiaru lub sprawdzały liczbę wartości NULL lub N/A dla wybranych atrybutów w konkretnych tabelach. W połączeniu z raportami, które wizualizowały zgromadzone rezultaty tych testów – według mnie sprawdzało się to całkiem dobrze. Niemożliwym wydaje się napisanie kilkunastu lub kilkudziesięciu testów dla każdej kolumny w hurtowni danych jednakże im bardziej szczegółowe są testy tym większe prawdopodobieństwo, że unikniemy problemów w przyszłości.
Database Verification Framwework powinien bez dodatkowych prac programisty przedstawić wiedzę o danych i ich zmianie we wszystkich tabelach i kolumnach. Oczywiście pisanie testów tSQLt lub testów o których mowa była we wcześniejszym akapicie to nadal świetny pomysł, natomiast wydaje się, że DVF może te testy uzupełnić oraz odciążyć i przyspieszyć.
Zakończenie
Praca z hurtownią danych, a już w szczególności z dużym i wymagającym projektem hurtowni danych nie jest rzeczą trywialną. Ryzyko wprowadzenia małej zmiany, która diametralnie zmieni dane jest stosunkowo wysokie. Taka niepożądana zmiana lub błąd nie zawsze może zostać wychwycona przez programistów czy nawet analityków i w ostateczności może to prowadzić do wyciągnięcia błędnych wniosków na podstawie błędnych danych. Ich wychwycenia nie jest zatem proste, a z powodu konieczności ewentualnych zmian lub przeładowywania danych i aktualizacji raportów czas gra ważną rolę Wydaje mi się, że Database Verification Framework może ułatwić i przyspieszyć proces wyszukiwania ewentualnych błędów w danych oraz reagowania na takie incydenty.
Jak wspomniano wyżej projekt będzie rozwijany i w przypadku dużej ilości zmian pojawi się kolejny artykuł. Zachęcam do śledzenia GitHub’a, aby być na bieżąco ze wszystkimi zmianami. Znajdują się tam również wszystkie kody źródłowe oraz raporty i pliki.
Link do GitHuba: https://github.com/seequality/seequality_database_verification_framework
Dajcie proszę znać w komentarzach z jakimi podejściami spotkaliście się w swoich projektach i oczywiście co uważacie o Database Verification Framework.
- Docker dla amatora danych – Tworzenie środowiska (VM) w Azure i VirtualBox (skrypt) - April 20, 2020
- Power-up your BI project with PowerApps – materiały - February 5, 2020
- Docker dla “amatora” danych – kod źródłowy do prezentacji - November 18, 2019


Last comments